Every comparison thread for the best AI face swap tools lists the same five products and ranks them differently every week. After spending a year building in this space, the rankings matter less than understanding why a swap looks real or fake. Once you know what breaks realism, picking a tool stops being guesswork.
This article breaks down what’s actually happening inside a modern face-swap pipeline, why most consumer tools converge on the same output quality, and which part of the pipeline still moves the needle on realism in 2026.
The thing most comparison posts don’t say
Most consumer AI face swap “tools” are the same tool.
Roop (released 2023) plus InSwapper (the swap network from InsightFace) is the foundation. Pull apart almost any modern consumer face-swap product and you’ll find the same two components underneath. The UI changes. The branding changes. The pricing tiers change. The swap network and detection front-end are identical.
We noticed this early when we were building iSamurai. We started on the same stack as everyone else — SCRFD-10G for detection, InSwapper for the swap — and we kept running into the same wall as Roop itself: detection failures on anything that wasn’t a frontal studio face. Every “competitor” was hitting the exact same ceiling, because they were running the exact same model.
This is why Roop-class tools all plateau at the same quality. It’s not a conspiracy — just the reality of which open-source models got good enough first, and the fact that the entire industry then wrapped them.
What actually decides realism
Three components decide whether a swap looks real. Every tool stacks up based on how well it handles each.
Detection quality
Before a swap can happen, the face has to be found. Every Roop-derived stack uses SCRFD-10G — fast, great on frontal faces, silently fails on turned heads, heavy shadow, partial occlusion.
A missed detection isn’t a “low-quality swap.” It’s no swap at all. The frame passes through untouched and your eye catches the discontinuity instantly.
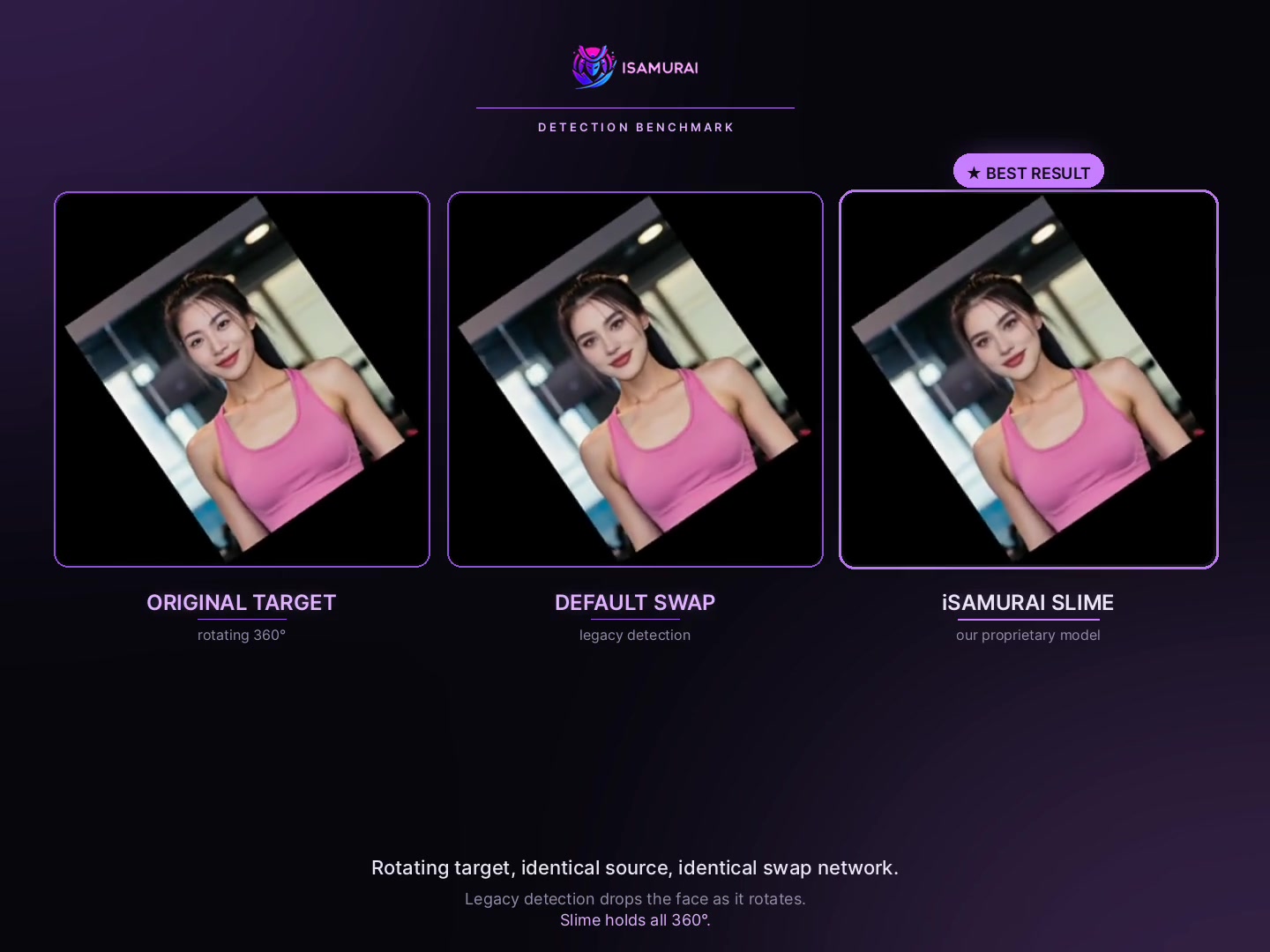
This was the specific wall that pushed us to rebuild the detection front-end. You can have the best swap network in the world, and it doesn’t matter if the upstream detector keeps losing the face. The video below shows the same source face, same swap network, on a target rotating through 360°. Legacy SCRFD-10G drops the face as it turns. Slime holds it.
Identity embedding precision
The swap model maps the source face into a vector — an “embedding” — and uses that vector to drive the generation. The dimensionality and training of that embedding space determine how well identity survives across frames.
- 256-dimensional embeddings are the legacy standard. Every Roop-class tool uses them.
- 512-dimensional embeddings with margin-based loss give noticeably tighter identity preservation, especially on difficult angles and longer clips.
It’s the difference between “that’s clearly the person” and “that’s someone who looks like the person.” On our Pro detection model, we use 512-dim specifically because we observed identity drift on the 256-dim default across long clips.
Blending and color matching
Even a perfect swap falls apart if the tool doesn’t match skin tone, lighting direction, and grain to the target frame. This is the part viewers notice but can’t articulate — “something’s off” usually means a blending failure, not a swap failure.
Good blending matches three things: average skin tone within the face mask, directional lighting (highlights and shadows pointing the same way as the rest of the scene), and film grain or compression noise. Skip any of these and the swap looks pasted-in even when the face geometry is correct.
The tools, briefly
A short, honest taxonomy of what’s available in 2026:
- iSamurai (ours). A consumer face swap tool running an in-house detection front-end (Slime-Mini default, Slime-Pro flagship) instead of SCRFD-10G, with 512-dim embeddings on Pro. Cloud-based, free for image swaps.
- FaceFusion. The best-maintained Roop-family tool. Active development, clean UI for a self-hosted tool. Output quality tracks Roop’s because the underlying models are Roop’s: SCRFD-10G + InSwapper. Self-hosted, requires GPU.
- Roop / Roop-Unleashed. The source. Most “new” consumer tools in this lane are forks or reskins. To see what Roop-class output looks like at its cleanest, use Roop directly.
- InSwapper-based cloud tools. Most “AI face swap” SaaS products fall here. Output quality is identical to Roop at best, often worse where compression is aggressive. Watermarks, resolution caps, and per-minute pricing are the differentiators — not model quality.
- Mobile face-swap apps. Roop’s swap network running on-device or via a thin API, aggressively downsized for mobile constraints. Entertainment-grade output. Resolution caps and compression make them unsuitable for realistic work.
- DeepFaceLab. The exception. Older architecture, but if you train per-identity for hours, the output ceiling beats everything else on that specific face. Not practical for casual use, but still the best option when you have one identity you need maximum realism on.
Why detection is the practical differentiator
Because the swap models have converged on InSwapper, realism differences between consumer tools now come almost entirely from before the swap happens — detection and embedding.
- If the detector misses frames, no swap happens on those frames. The viewer sees the original face flicker through.
- If the embedding is coarse, identity drifts across rotation and lighting changes. The swapped face stays similar but stops being the same person.
- If the blending is lazy, skin tone mismatches and the swap looks pasted in.
The first two are upstream of the swap network entirely. The tool with the best upstream stack wins — not because its swap model is better (it isn’t, almost everyone is running InSwapper), but because the input to that swap model is cleaner.
This is what we optimized for in iSamurai. Same InSwapper underneath, but a detector that actually finds non-frontal faces and an embedding space large enough to preserve identity across rotation, lighting shifts, and long clips.
How to test a face swap tool before committing
Before you pay for a subscription or invest hours in a self-hosted setup, test the tool on hard content, not on the demo reel:
- A turned-head clip — at least 30° of yaw. Frontal demos hide every detection weakness; profiles expose them.
- A 30+ second clip — short clips hide identity drift. Across a longer clip you can see whether the face stays the same person or slowly becomes someone else.
- A dark scene — shadows expose blending weakness fast. If the swap goes flat or wrong-toned in low light, the blending is lazy.
- A multi-person scene — does the tool let you map different sources to different faces, or does it pick one?
If the tool handles all four, the underlying stack is solid. If it only looks good on a frontal talking-head demo, assume you’re looking at a Roop wrapper and the ceiling is what Roop ships.
FAQ
Are all AI face swap tools really the same model underneath?
Most consumer ones, yes — or close variants of the same InSwapper + SCRFD-10G stack that Roop popularized in 2023. The exceptions are proprietary implementations (iSamurai’s Slime detection stack is one example) and older specialist tools like DeepFaceLab that predate Roop entirely.
Why is detection the bottleneck and not the swap model?
Because a missed detection produces no output. The swap network only runs on frames where the detector found the face. If detection drops a frame, the original frame passes through untouched — which is visually worse than any degraded swap. SCRFD-10G drops a lot of frames on real-world (non-studio) content, which is the ceiling most consumer tools hit.
What makes the Slime detection stack different from SCRFD-10G?
Three things: a higher-dimensional embedding space (512-dim vs 256-dim on the Pro variant), margin-based classification loss for tighter identity separability, and training data rebalanced toward non-frontal, low-light, and occluded faces. Inference cost is similar on Slime-Mini and roughly 1.5× on Slime-Pro.
If the swap network is the same, can the output really differ that much?
Yes — by a lot. Cleaner detection produces cleaner landmarks, which produce cleaner embeddings, which produce cleaner swaps. Garbage into InSwapper produces garbage out of InSwapper. The swap model isn’t a magic equalizer.
Is it worth paying for a cloud tool if Roop is free?
It depends on your content. If you’re swapping frontal talking-head clips, Roop self-hosted gives you the same output at zero marginal cost. If you have non-frontal, varied-angle, or multi-face content, the Roop ceiling becomes frustrating fast — that’s where a different detection stack earns its keep.
What about DeepFaceLab? Is it still relevant?
Yes, for one specific use case: if you have a single identity you need maximum realism on and you’re willing to train a model for hours per face, DeepFaceLab’s output ceiling still beats everything else on that face. It’s a different category of tool — not competing on convenience, competing on per-identity ceiling.
How do I know if a tool is just Roop with a different logo?
Two tells: every demo on the marketing page is a frontal talking head, and the tool has no public technical write-up of its detection or embedding architecture. Roop wrappers don’t publish architecture details because there’s nothing custom to publish.
What’s the realism chain I should optimize for?
Detector → embedding → swap network → blending. The weakest link decides what your viewer sees. In 2026, for most consumer tools, that link is the detector. Pick the tool whose detector holds up on your actual content.
Try it
Test the iSamurai detection stack on your own hard clip — turned heads, multi-face, dark scenes. Open the iSamurai AI face swap tool, free for image swaps. Log in or sign up to save results to History.